Imagine you find a website — maybe a production site or one still in development. After browsing its folders, the site has no links to anything else and gives no clues to more pages. So it looks like our only option is to fuzz the website. The term fuzzing refers to a testing technique that sends various types of user input to a certain interface to study how it would react.
Well — when it comes to fuzzing, I honestly don’t know which section to put it in, because it sits between enumeration and exploitation. When fuzzing is treated as part of enumeration, it’s the actions we use to probe for parameters in a web app or to discover hidden directories. If you consider fuzzing as part of exploitation, it’s the process of sending unexpected or malformed inputs to trigger vulnerabilities — the stuff that can cause crashes, reveal memory, or lead to code execution.
Okay — in this post I’ll focus on fuzzing as part of enumeration: using these techniques to find hidden directories or parameters used by a website so they can be leveraged later.
Web servers usually don’t expose a directory of all available links and paths (unless badly configured), so we have to probe different URLs and see which ones return pages. For example, if we visit https://www.zed99.net/doesnotexist we’ll get an HTTP 404 “Not Found.” However, if we visit a page that exists — like /login — we’ll see the login page and get an HTTP 200 OK.
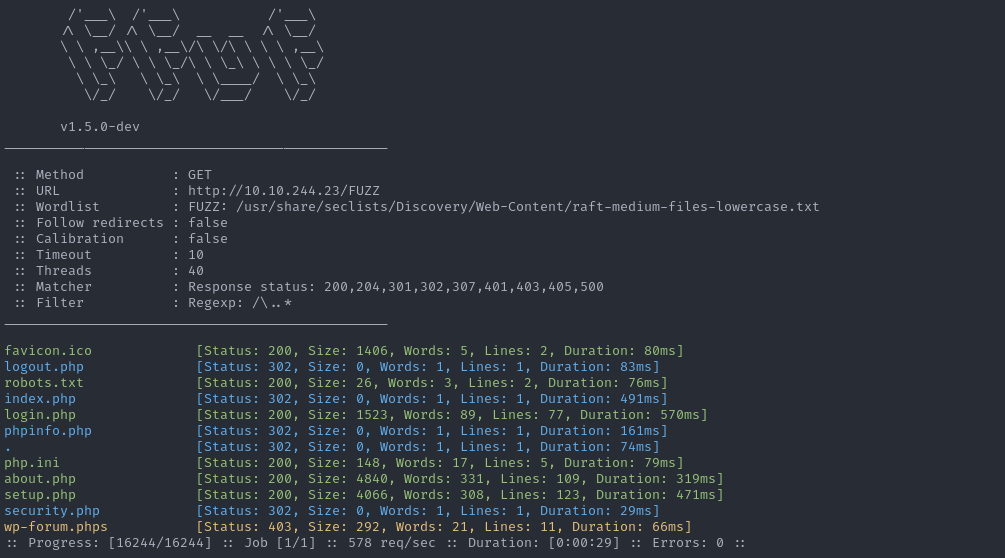
This is the basic idea behind web fuzzing for pages and directories. Still, we cannot do this manually, as it will take forever. This is why we have tools that do this automatically, efficiently, and very quickly. Such tools send hundreds of requests every second, study the response HTTP code, and determine whether the page exists or not. Thus, we can quickly determine what pages exist and then manually examine them to see their content.
To determine which pages exist, we should have a wordlist containing commonly used words for web directories and pages, very similar to a Password Dictionary Attack. I will not have to reinvent the wheel by manually creating these wordlists, as great efforts have been made to search the web and determine the most commonly used words for each type of fuzzing. Some of the most commonly used wordlists can be found under the GitHub SecLists repository, which categorizes wordlists under various types of fuzzing, even including commonly used passwords.
There are many tools and methods to utilize for directory and parameter fuzzing/brute-forcing. In this module we will mainly focus on the ffuf tool for web fuzzing, as it is one of the most common and reliable tools available for web fuzzing.